<테스트 진행 방법>
오토스케일링 할 대상 서버를 선정한 후, 해당 서버의 이미지를 떠놓습니다.
그리고 나서 cpu 평균 사용률, 메모리 평균 사용률에 따라 서버의 대수가 설정해놓은 최소, 최대 갯수로 늘고 줄어들게끔 설정을 합니다.
Auto Scaling > Launch Configuration에서 오토스케일링을 위한 서버 템플릿 생성합니다.
서버 이미지는 대상 서버의 이미지를 통해 내 서버이미지를 만들어 놓으면 됩니다.

오토스케일링 그룹을 생성합니다.
아까 만든 Launch Configuration 서버 템플릿을 선택하고 최소 용량, 최대용량, 기대용량을 설정해줍니다.
기대용량이 최소용량보다 작으면 안됩니다.

이제 이 오토스케일링 그룹을 대상으로 이벤트 룰을 생성할 것입니다.
cloud insight > event rules 생성 > auto scaling group 선택

1. 감시 대상 그룹을 설정해줍니다.

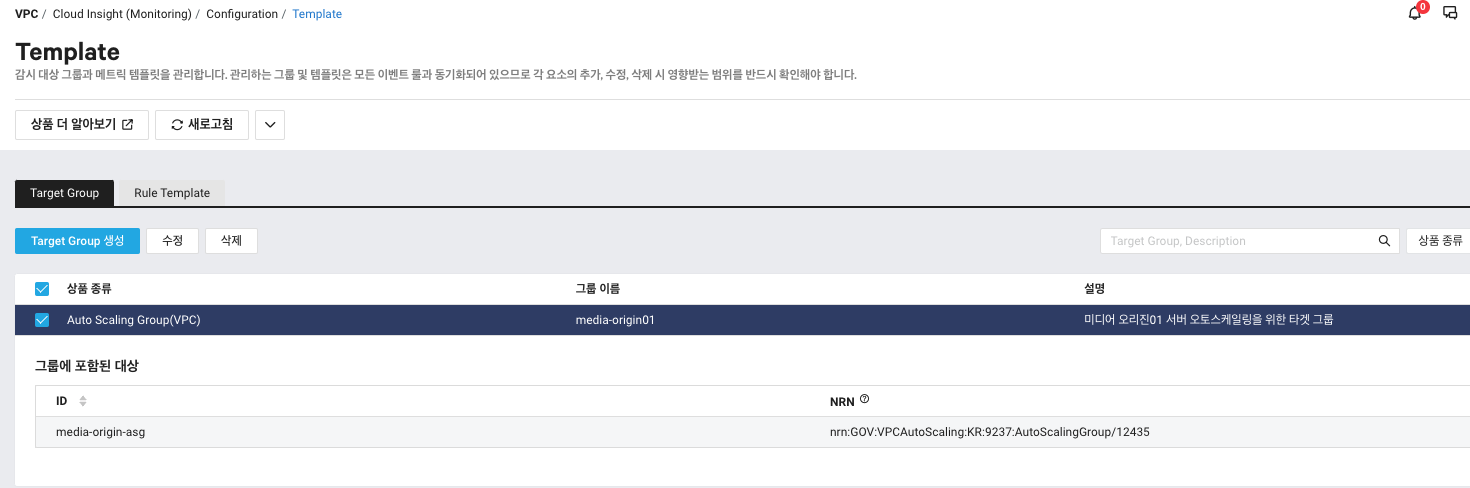
2. 감시 항목 및 조건 설정
감시 항목을 설정합니다. 기본으로 제공하는 감시 템플릿을 선택하거나, 감시 목적에 따라 각 타입별 감시 항목을 선택해서 나만의 감시 템플릿을 생성할 수 있습니다.
저는 저만의 rule template 를 생성하겠습니다.
저는 메모리 평균 사용량이 40% 이상이 1분 지속되면 서버 증가, 40% 이하가 1분 지속되면 서버 감소 되도록 설정을 해놓았습니다.


마찬가지로 cpu 평균 사용량이 40% 이상이 1분 지속되면 서버 증가, 40% 이하가 1분 지속되면 서버 감소 되도록 설정을 해놓았습니다.


3. 액션설정
이벤트 발생 시 다양한 채널의 액션을 실행하도록 설정할 수 있습니다. 채널별로 다수 개의 액션을 선택할 수 있으며, 각 채널별로 실행 시간은 차이가 있을 수 있습니다.
알림 메시지 발송, intergration, Auto Scaling 정책 등을 설정할 수 있습니다.
통보 대상자 그룹 그리고 오토스케일링 정책 액션을 설정합니다.


이런식으로 이벤트룰을 생성해줍니다.

이제 stress 툴을 통해 cpu, memory 에 부하를 주었다가 멈추어 auto scaling이 제대로 되는지 테스트를 진행해보겠습니다.
stress 툴이 설치 안되어있다면 apt install stress, yum install stress 를 입력하여 설치 먼저 진행해주세요.
<stress 툴을 이용하여 CPU에 부하>
sudo stress --cpu 8 --timeout 180
Cloud insight > Service Dashboard 에서 Auto Scaling Group(VPC)을 선택하여 CPU Utilization Average를 확인해보면 평균 사용량이 50프로까지 올라간 모습을 확인할 수 있다.

cpu 평균 사용량이 40% 이상이 1분 지속되면 서버 1대를 더 늘리도록 설정해놓았기 때문에 서버가 늘어난 모습을 볼 수 있다.

시간이 지나서 cpu 평균 사용량이 40% 이하로 떨어지니 다시 서버가 줄어들었다.

<stress 툴을 이용하여 메모리에 부하>
sudo stress --vm-bytes 16384m --vm-keep -m 6 --timeout 180s
Cloud insight > Service Dashboard 에서 Auto Scaling Group(VPC)을 선택하여 Memory Utilization를 확인해보면 평균 사용량이 51프로까지 올라간 모습을 확인할 수 있다.

메모리 평균 사용량이 40% 이상이 1분 지속되면 서버 1대를 더 늘리도록 설정해놓았기 때문에 서버가 늘어난 모습을 볼 수 있다.

시간이 지나서 메모리 평균 사용량이 40% 이하로 떨어지니 다시 서버가 줄어들었다.

이렇게 cpu 평균 사용량, 메모리 평균 사용량에따른 auto scaling을 실행해보았습니다.
auto scaling group 에서 만들어진 서버에 대해서만 메트릭이 집계되니 참고 부탁드립니다.
다음에 더 유용한 내용으로 돌아오겠습니다~
'NaverCloud Platform' 카테고리의 다른 글
| Percona Monitoring andManagement(PMM) 설치 및 사용 (0) | 2024.06.05 |
|---|---|
| [Naver Cloud Platform] Database Migration Service으로 DB 마이그레이션 (1) | 2023.09.15 |
| [Naver Cloud Platform] CLA(Cloud Log Analytics) 사용 (0) | 2023.08.22 |
| [Naver Cloud Platform] 리눅스 패스워드 expired 정책 해제 (0) | 2023.08.21 |
| [Naver Cloud Platform] ALB redirection 하는법 (0) | 2023.08.21 |